

AI-901(Azure AI Fundamentals)のドメイン1で問われる「AIモデルのコンポーネントと構成」。ここでは大きく3つ——①生成AIモデルが動くしくみ ②用途に合うモデルの選び方 ③デプロイと設定パラメーター——が出ます。むずかしい数式は不要。「AIが文章をどう作り、どう選んで、どう調整するか」を、身近なイメージでつかみましょう。

そもそも「AIモデル」って何?
AIモデルとは、大量のデータからパターンを学んだ「予測する仕組み」のことです。たとえば「ね・こ・が・…」と来たら、次は「鳴いた」かな、と続きを予測します。中でも生成AIは、学んだことをもとに新しいコンテンツ(文章・画像・音声など)を作り出すAIです。ChatGPTのようなチャットAIは、この生成AIの代表例です。

生成AIが文章を作るしくみ(4ステップ)
生成AIが文章を作る流れは、ざっくり次の4ステップです。
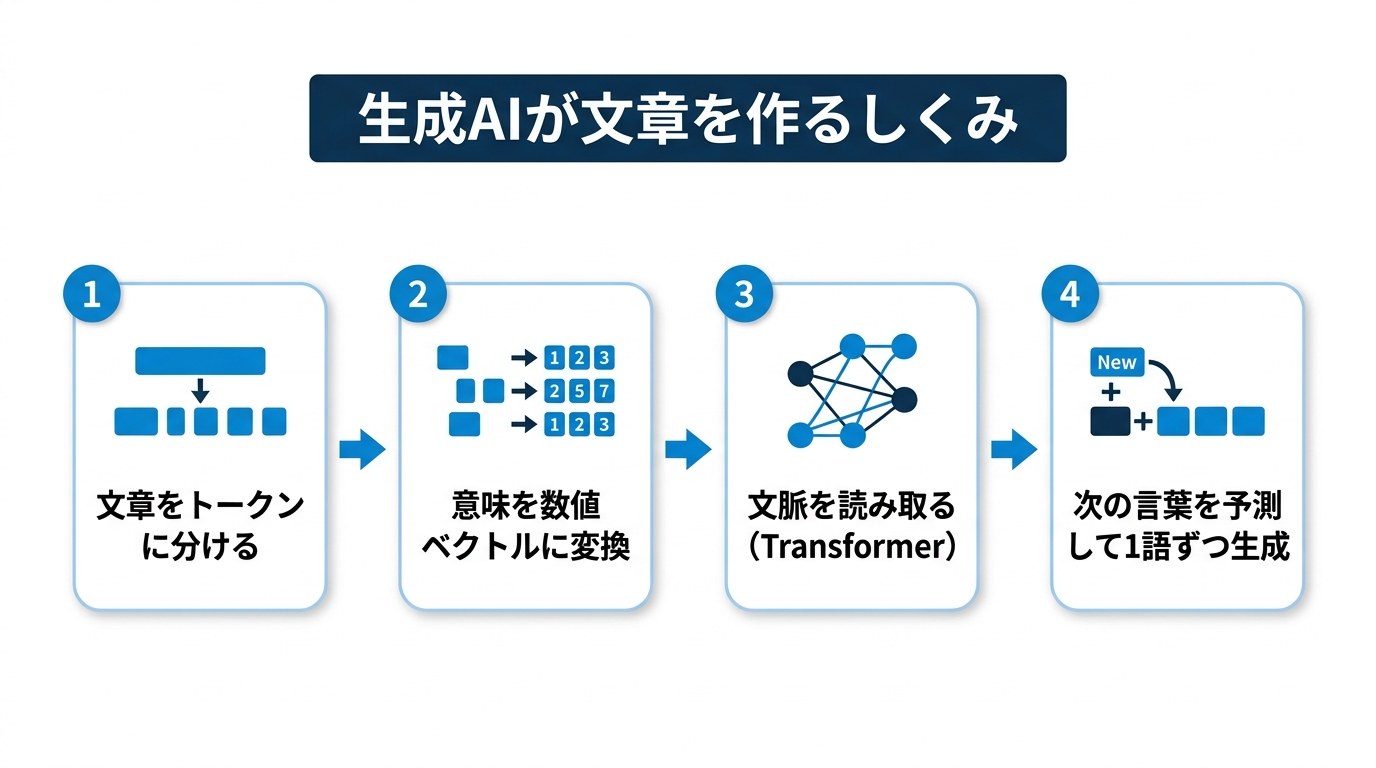
- 文章をトークンに分ける:AIは文章をそのままではなく、「トークン」という小さなかたまり(単語や文字の一部)に分けて扱います。トークンは料金や長さの単位にもなります。
- 意味を数値(ベクトル)にする:各トークンの意味を数字の並び(ベクトル)で表します。これを埋め込み(embedding)といい、意味が近い言葉は数値も近くなります(例:「犬」と「猫」は近い)。
- 文脈を読み取る(Transformer):Transformer(トランスフォーマー)という仕組みが、トークン同士の関係を見て文脈(どの言葉がどの言葉に関係するか)をつかみます。
- 次の言葉を予測して生成:ここまでの流れから「次に来る可能性が高いトークン」を選び、1語ずつつなげて文章を作ります。
用途に合うモデルの選び方
AzureのAI開発ツール「Microsoft Foundry」には、たくさんのAIモデルが並ぶ「モデルカタログ」があります。その中から用途に合うモデルを選んで使います。選ぶときの観点は次の5つです。

- モダリティ:何を入力・出力するか。テキスト生成/画像生成/埋め込み(検索向け)/音声など、目的に合った種類を選ぶ。
- 能力:どれだけ賢く・正確か。難しいタスクほど高性能なモデルが必要。
- コスト:高性能なモデルほど料金が高い傾向。用途に対して過剰でないか。
- 速度(レイテンシ):応答の速さ。チャットなど即時性が要る用途では重要。
- コンテキスト長:一度に扱えるトークンの量。長い資料を丸ごと読ませたいなら、コンテキスト長が大きいモデルを選ぶ。
ポイントは「いつも最高性能を選べばよいわけではない」こと。能力・コスト・速度のバランスを、用途に合わせて取るのが正解です。
モデルのデプロイと構成パラメーター
使いたいモデルを選んだら、デプロイします。デプロイとは、モデルを「使える状態」にして、呼び出すための窓口(エンドポイント)を作ることです。Foundryでは、主に次の2つの方法があります。
- サーバーレス API:従量課金(使った分だけ支払い)で、Microsoftが管理するインフラ上のモデルをAPIとして手軽に使う方法。自分でサーバーを用意せず、低コスト・かんたんに始められます。
- マネージド計算(専用コンピュート):モデルを専用の計算リソースにホストする方法。専有できるぶん、要件が厳しい場合などに使います。
さらに、答え方を調整する構成パラメーターがあります。代表がtemperature(テンパラチャー/温度)です。
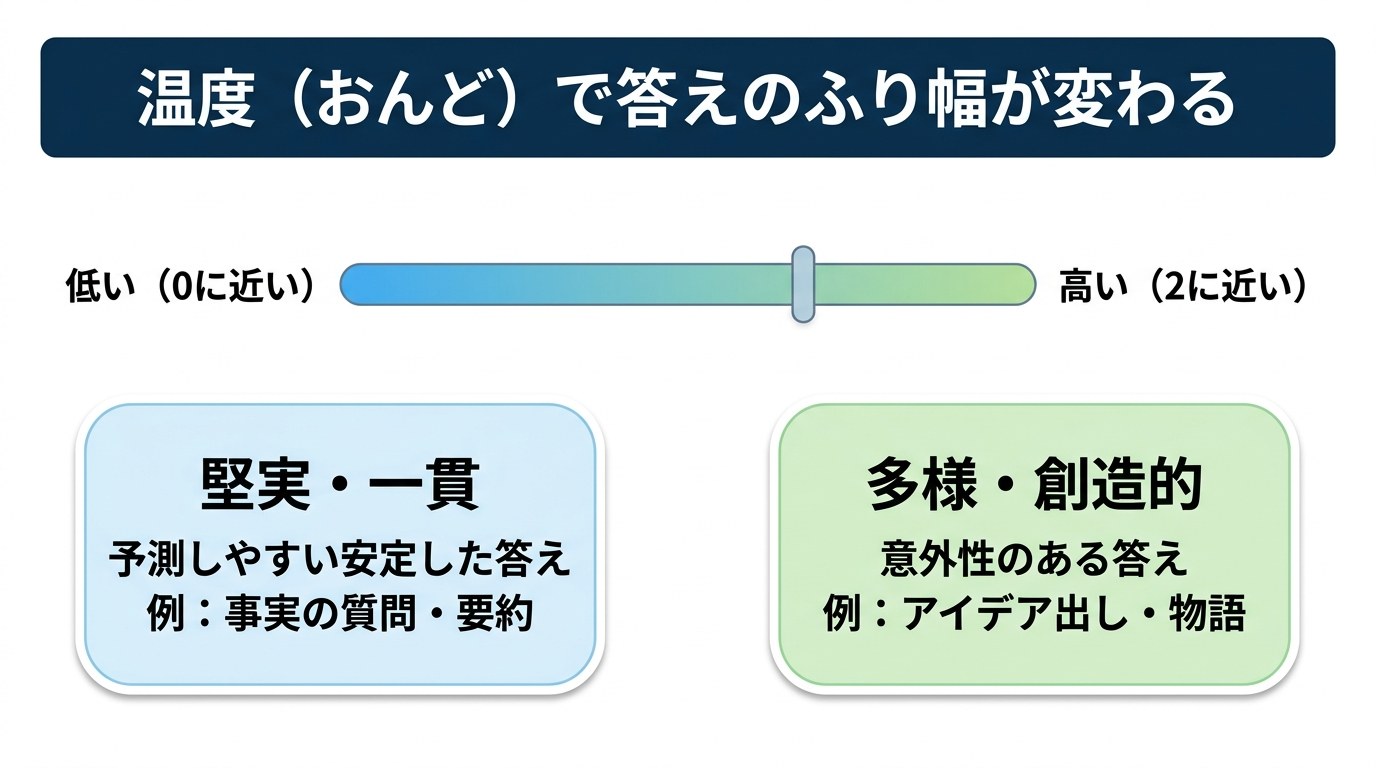
- temperature(温度):答えの「ふり幅(ランダムさ)」を調整。低い(0に近い)=堅実で一貫(事実確認・要約向き)、高い=多様で創造的(アイデア出し・物語向き)。値は0〜2で、既定は1.0です。
- top_p:temperatureとは別の、ふり幅の調整方法(上位の候補だけから選ぶ)。temperatureとtop_pは、両方ではなくどちらか片方を調整するのが推奨です。
- 最大トークン数(max tokens):1回で生成する最大の長さ。長く答えさせたいときは大きく設定します。
確認クイズ
Q1. 生成AIが文章を作るとき、基本的にどうやって次の単語を決めますか?
Q2. AIが文章を分けて扱う、小さなかたまりの単位を何と呼びますか?
Q3. 事実確認や要約のため、答えを「堅実で一貫」させたいとき、temperatureはどうしますか?
Q4. 自分でサーバーを用意せず、従量課金でモデルをAPIとして手軽に使いたい。Foundryのどのデプロイ方法?
よくある質問(FAQ)
Q. 「トークン」って結局なんですか?
A. 文章を分けた小さなかたまりです(単語や文字の一部)。AIはトークン単位で処理し、料金や入出力の長さもトークン数で数えます。日本語はおおよそ1文字=1〜2トークン程度が目安です。
Q. temperatureとtop_pは両方調整していいですか?
A. どちらか片方の調整が推奨です。両方を同時に動かすと効果が読みづらくなります。まずはtemperatureだけで十分です。
Q. 結局どのモデルを選べばいいですか?
A. まず用途(モダリティ)で絞り、つぎに能力・コスト・速度・コンテキスト長のバランスで決めます。Foundryのモデルカタログで比較できます。「とりあえず一番高性能」ではなく、用途に見合うものを選ぶのがコツです。
まとめ
- 生成AIのしくみ=トークン化 → 埋め込み(数値化)→ Transformerで文脈把握 → 次のトークンを予測
- モデル選び=モダリティ・能力・コスト・速度・コンテキスト長のバランス(Foundryのモデルカタログ)
- デプロイはサーバーレスAPI(手軽・従量課金)とマネージド計算(専用)。temperature低=堅実/高=創造的
この記事はAI-901の学習範囲の一部です。どの順番で・何時間くらい勉強すればよいかは、AI-901の勉強方法・独学ロードマップで全体像を解説しています。迷ったらここから確認するのがおすすめです。
- ➡ 前の記事:責任あるAIの6原則
- ➡ つぎは「AIワークロードの種類」(準備中)
- ➡ AI-901対策トップ / 試験概要・受験ガイド
※本記事はMicrosoft公式ドキュメント(生成AIのしくみ/Foundryのモデル・デプロイ/推論パラメーター)およびAI-901公式試験ガイドに基づき、エンジニアKが作成しています。製品仕様は更新されるため、最新は Microsoft公式情報 をご確認ください。

